GEMM Evolution: CUDA suite with 13 kernels
Nov 29, 2025
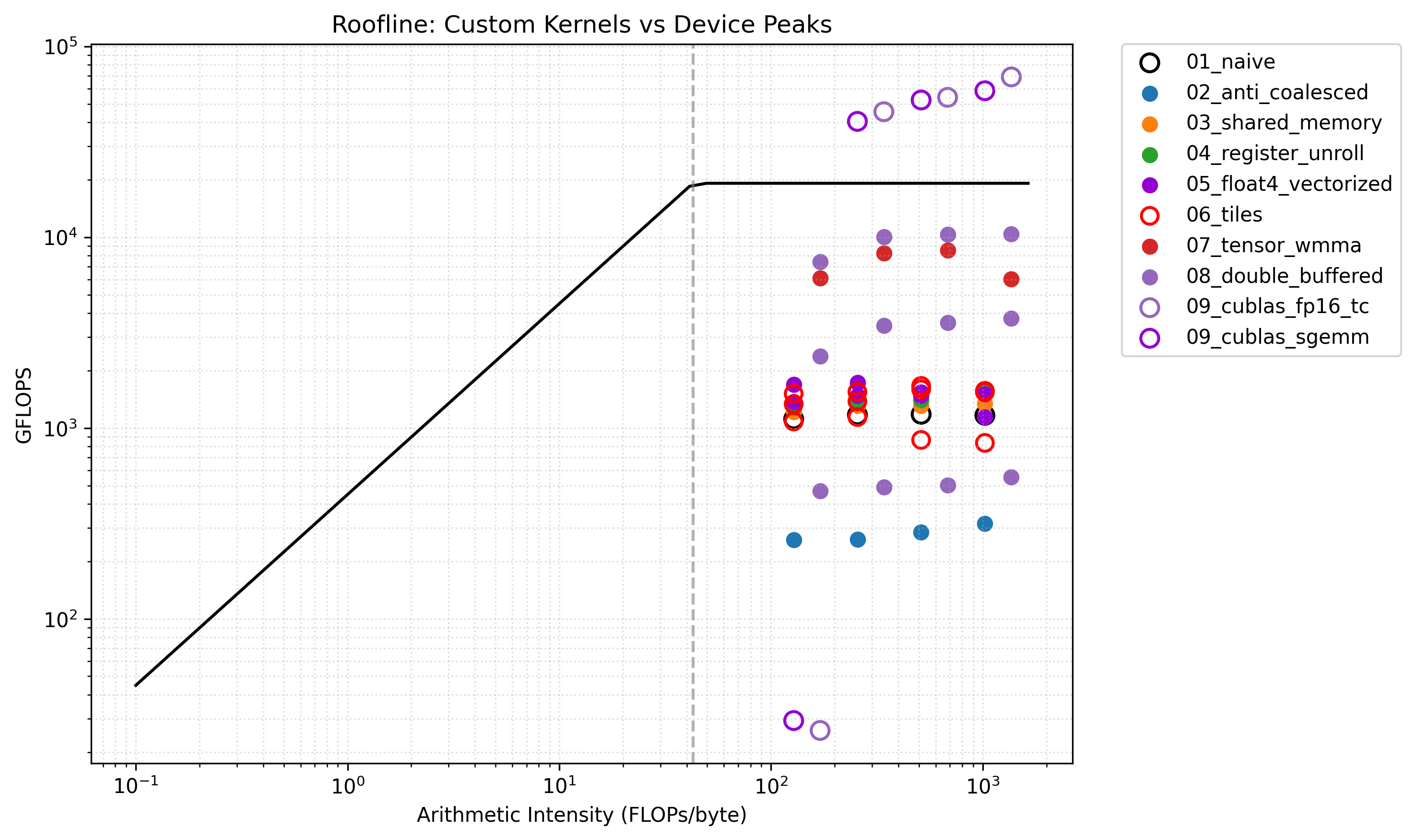
GEMM Evolution is a progressive CUDA suite of 13 GEMM kernels. It demonstrates a sequence of optimizations and design patterns (naive → tiled → vectorized → WMMA → cp.async double buffering) and provides a unified runner for automated benchmarking and visualization.
Highlights
- Best custom kernel throughput:
08_double_buffered_cdemonstrates the highest custom-kernel GFLOPS at large sizes — compute-bound (arithmetic intensity ≫ roofline ridge). - Library reference:
cuBLASachieves very high GFLOPS at N = 8192, serving as a practical upper bound for comparison. - Occupancy trends: Warp-level WMMA and large thread-blocks can reduce occupancy; double buffering helps balance resources and utilization.
- Bandwidth scaling: Observed GB/s often decreases with matrix size while AI increases; at large matrices reuse and compute dominate performance.
You can see the full project on my GitHub here.