Radix Sort & Top-P Sampling Kernels in LLMs
Feb 17, 2026
Whenever you interact with ChatGPT, Gemini, or any modern LLM, the final inference step determining response speed is top-p (nucleus) sampling - the algorithm that selects tokens from the model’s vocabulary.
I’ve conducted CUDA kernel profiling analysis of this critical sampling operation. The results reveal a clear performance bottleneck.
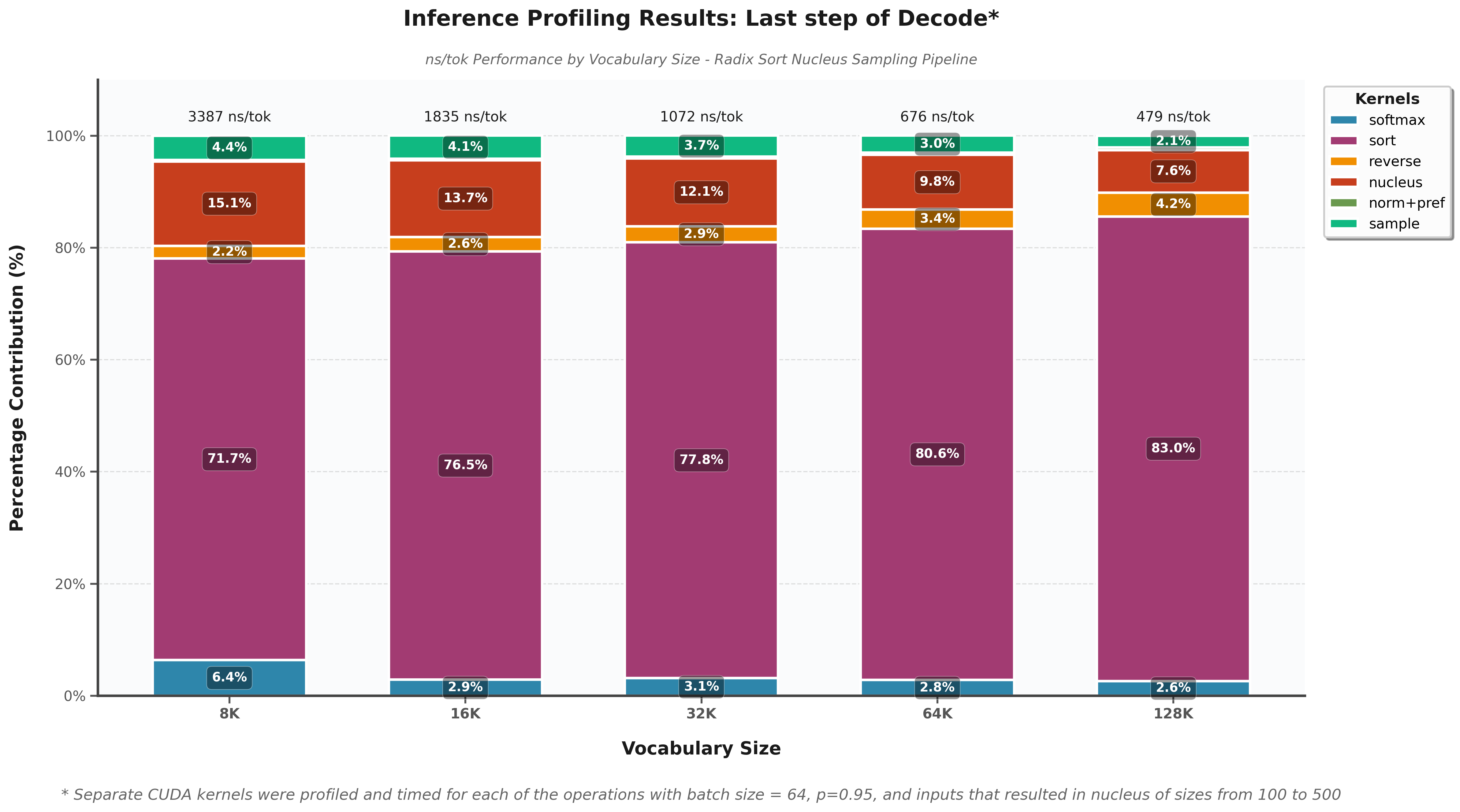
📊 Radix sort dominates execution time (71-83% of total processing) and becomes increasingly problematic with larger vocabularies, reaching up to 83% of total time at 131K vocabulary size.
This bottleneck presents a significant optimization opportunity for improving LLM inference latency.
You can see the full analysis and code: here.