Long Scoreboard Warp Stalls in Radix
Feb 25, 2026
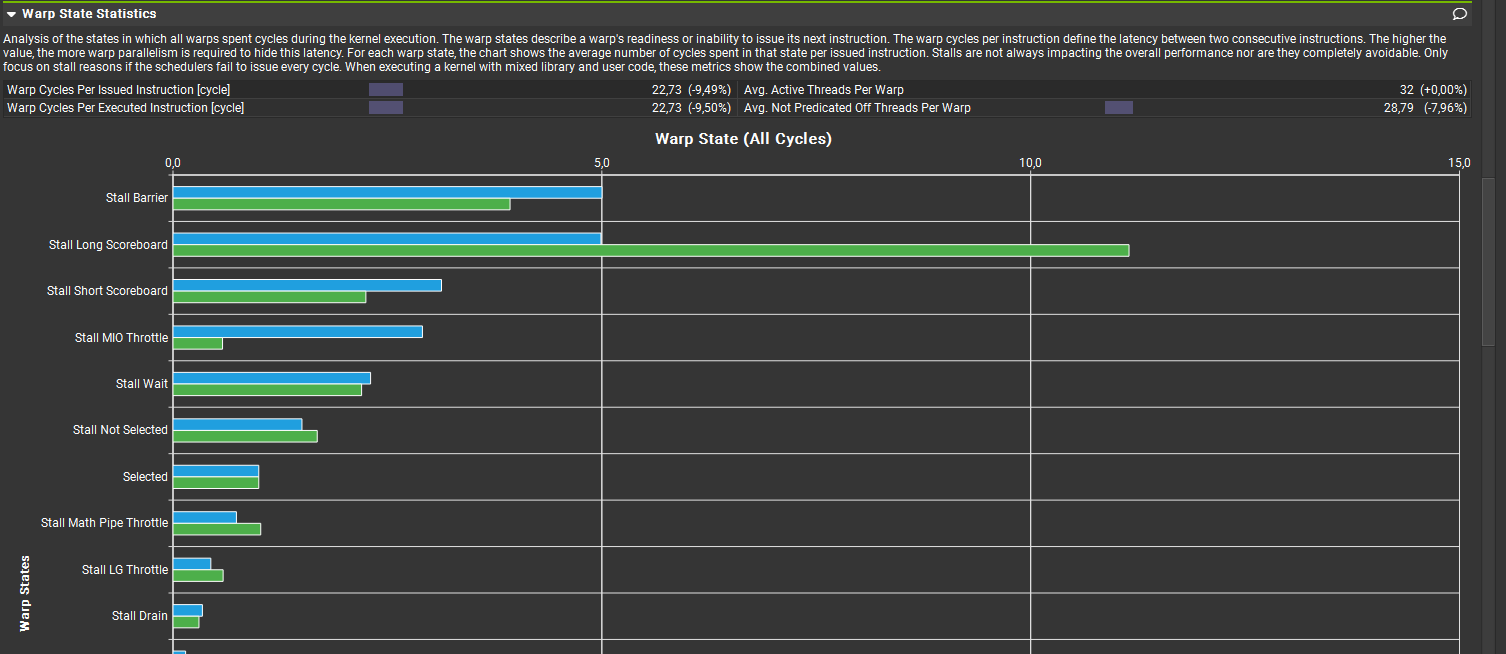
Optimized a custom radix-sort pipeline using Nsight Compute. Profiling Warp State Statistics and uncoalesced global accesses reduced long-scoreboard stalls by over 50%, illustrating GPU memory-hierarchy trade-offs and optimization trade-offs.
Highlights
- Root cause: Uncoalesced global loads/stores triggered 11+ cycle stalls per warp (Warp State Statistics).
- Fixes attempted: Moving hot inputs to
SRAMreduced long-scoreboard stalls by ~50% but surfaced new bottlenecks (barriers, short-scoreboards) that require synchronization and algorithmic attention. - Trade-offs: The prefix kernel incurred ~20% slowdown due to sparse writes — this needs an algorithmic redesign to recover performance while preserving overall correctness.
- Outcome: SRAM utilization improved and the radix kernel remained stable; the work highlights the iterative, trade-off-driven nature of CUDA performance tuning.
See the kernel code on GitHub: radix_v2.cu and the full analysis: run2 results.