Int8 Flash Attention: smaller blocks = higher occupancy
Mar 06, 2026
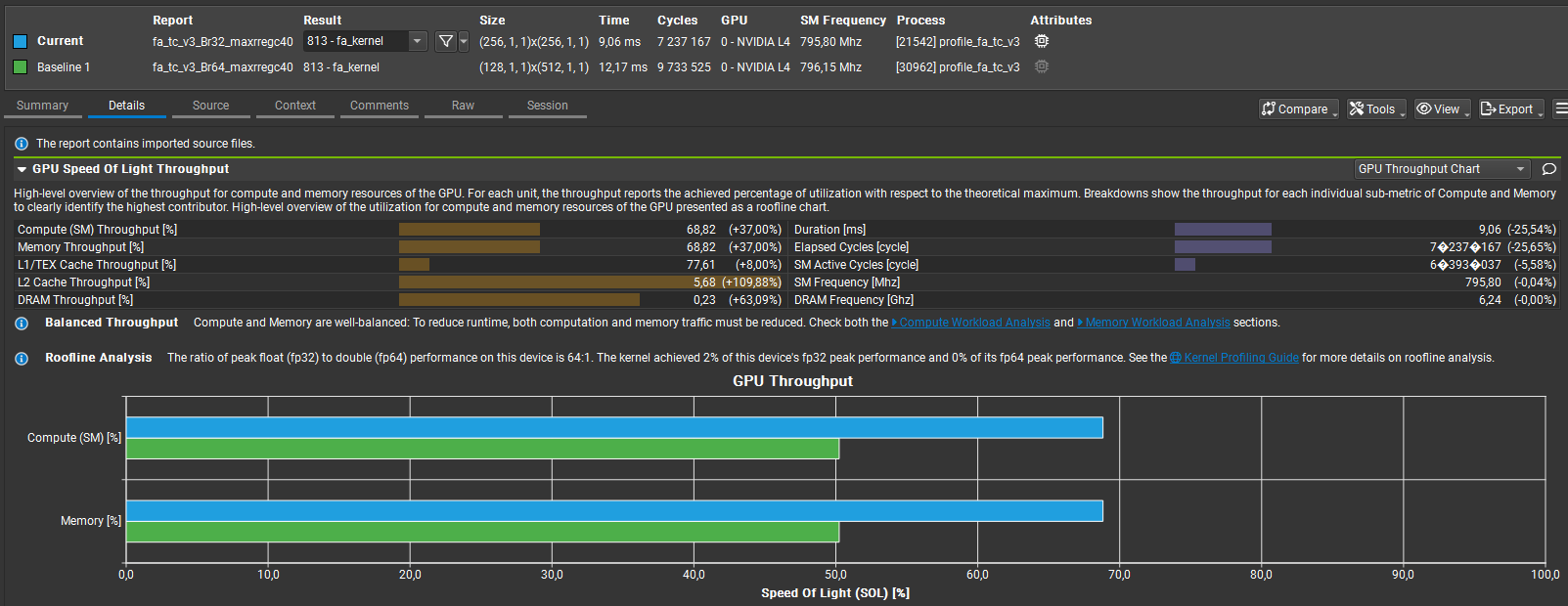
Compared Br=32 vs Br=64 for my custom int8 Flash Attention kernel. Top-line: Br=32 = 9.06 ms vs Br=64 = 12.17 ms → ≈25% faster Memory throughput: ≈69% vs ≈50% → ~38% higher; L2 throughput ≈2.1× higher Compute & memory % of peak both rose ≈50% → ≈69% (better utilization)
Why: Br=64 uses more shared memory/registers per block, reducing resident blocks/SM and amplifying load imbalance and unavoidable per-warp accumulation barriers (guarded by if(warp_tile_col_id==0]). Br=32 fits more blocks/SM, boosts L2 locality, and yields better real-world throughput.
See the kernel code on my GitHub here, the full analysis here and the summary of how I performed quantization here.
Highlights
- Occupancy: Br=32 increases block/SM residency and L2 locality, improving real throughput.
- Resource Pressure: Br=64’s higher shared-memory/register use reduces resident blocks and causes imbalance.
- Synchronization: Per-warp accumulation guard (if(warp_tile_col_id==0)) forces unavoidable barriers and stalls.
- Bank Conflicts: Splitting work across warps creates shared-memory bank hotspots that serialize accesses.
- Compile Tradeoff: Using -maxrregcount=40 raised residency but induced register spilling and extra memory traffic.
- Next: Port Int8 to fa_tc_v1 (single-warp) and focus on padding/re-indexing or swizzled accesses to remove conflicts.