Twelve Parallel Reduction Kernels
Mar 07, 2026
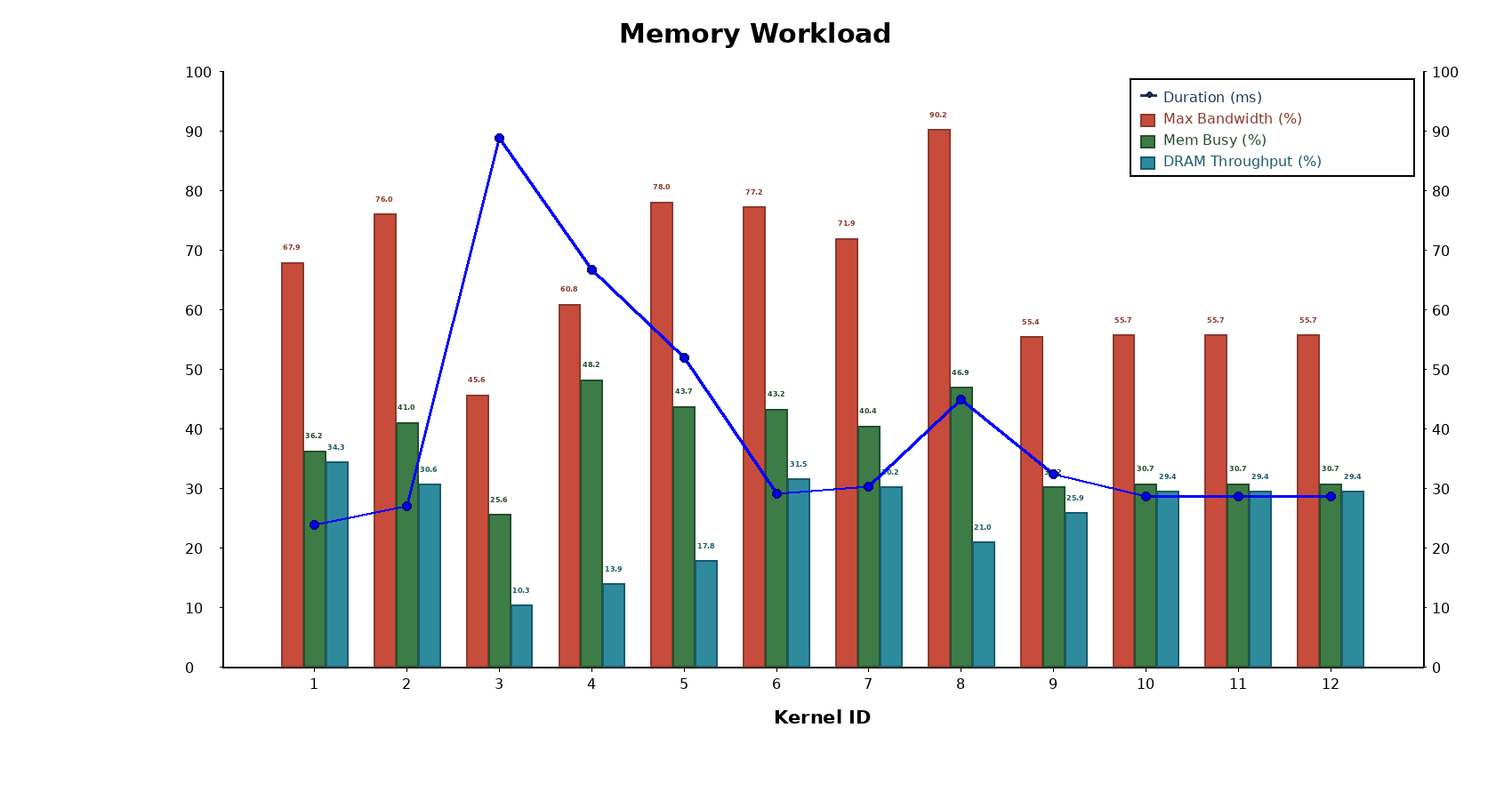
CUDA benchmark suite implementing 12 parallel-reduction kernels with comprehensive Nsight Compute analysis and charts comparing latency, memory throughput, scheduler stats, and instruction/source counters. The results show bandwidth-bound behavior where the highest DRAM throughput (the atomic_global kernel) yields the best runtimes, while divergence and instruction overhead (e.g., interleaved_addr_divergent_branch) severely hurt performance.
See the kernels on my GitHub here, the full analysis here and an Nsight Compute comparison of the best and worst kernels here.
Highlights
- Key Result: atomic_global beats interleaved_addr_divergent_branch by ~3.7× at large N (measured N≈1.07B).
- DRAM Impact: DRAM throughput is the dominant lever (example: memory throughput rises from ~33→110 GB/s in the faster variant).
- Instruction Reduction: Faster kernels issue far fewer instructions (issued/executed drop ≈90%), cutting overhead.
- Divergence Cost: Branch-heavy/uncoalesced designs explode instruction counts and drive stalls via warp divergence.
- Occupancy Caveat: Higher occupancy alone isn’t sufficient — lower occupancy can win if it increases effective DRAM throughput.
- Reproducibility: Full NCU reports, plots, build/profile scripts, and a PyTorch extension are included for easy validation and integration