Capacity-aware Sparse MoE
SparseMoE run1 profiling shows fused kernels vastly outperform unfused: the unfused workflow spends ~2034 ms dominated by WMMA up_proj/Swiglu/down_proj kernels, while the fused baseline variant runs in ~54 ms and the capacity aware version in ~37 ms. Capacity-aware per-expert buffering substantially improves compute/memory balance (≈46% speedup vs baseline) by reducing redundant DRAM↔shared copies and improving locality.
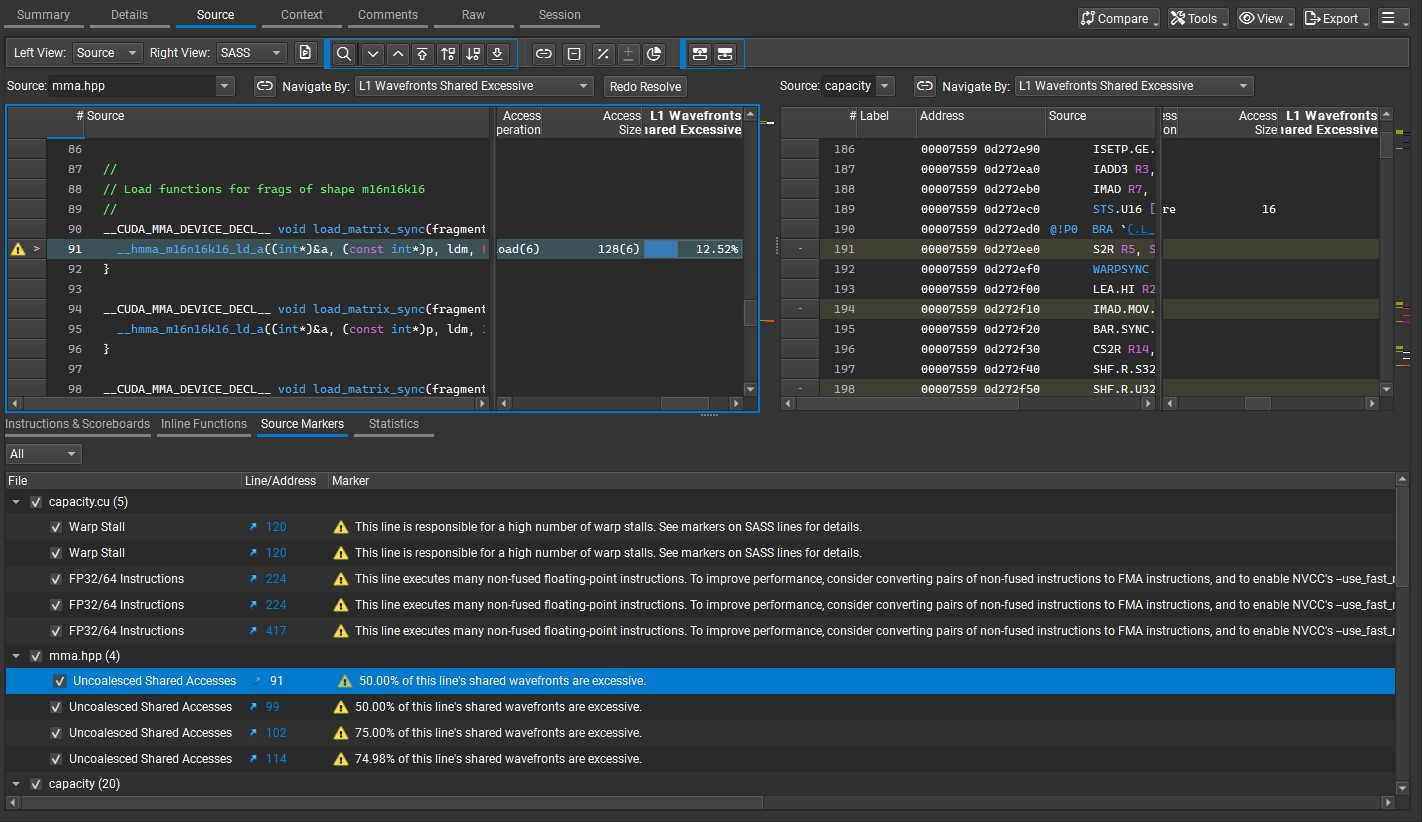
Nsight Compute points to uncoalesced cp.async.ca.shared.global copies and WMMA load paths as primary hotspots, and flags a redundant __syncthreads() after cp.async.wait_group that contributes ~58% of warp stalls. Next steps are to remove unnecessary barriers, tighten per-expert buffering, and focus WMMA kernels for further gains.
See the full analysis on my GitHub here, and the kernels: unfused.cu, baseline.cu and capacity.cu.
Highlights
- Performance: Fused (capacity) dramatically outperforms the unfused workflow.
- Capacity: Per‑expert buffering reduces redundant DRAM↔shared copies and evens load.
- Hotspots: cp.async.ca.shared.global copies and WMMA load paths are the primary sources of stalls.
- Synchronization: Redundant __syncthreads() after cp.async.wait_group drives ~58% of warp stalls.
- Memory ↔ Compute: capacity shifts the kernel from DRAM‑bound toward better compute/cache utilization.
- Next Steps: Remove the redundant barrier, tighten per‑expert sizing, and optimize WMMA kernels/padding.